![[レポート]従来の機械学習と生成型AIを上手に使った最適なアプローチ方法を考える #AWSReInvent #DPR201](https://images.ctfassets.net/ct0aopd36mqt/3IQLlbdUkRvu7Q2LupRW2o/edff8982184ea7cc2d5efa2ddd2915f5/reinvent-2024-sessionreport-jp.jpg?w=3840&fm=webp)
[レポート]従来の機械学習と生成型AIを上手に使った最適なアプローチ方法を考える #AWSReInvent #DPR201
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
こんにちは、せーのです。
AWS Re:Invent2024、今回はDPR201ワークショップ「Finding the right approach: Bridging traditional ML with generative AI」のレポートをお送りします。

セッション概要
このハンズオン形式のワークショップでは、従来の機械学習アプローチと新興のジェネレーティブAIの領域との相乗効果を探ります。
AWS DeepRacerで使用されている強化学習の概念との類似点を踏まえ、このワークショップでは、従来の機械学習かジェネレーティブAIかに関わらず、適切なソリューションを選択するための基準について掘り下げていきます。
Amazon BedrockやAmazon Qのようなローコード/ノーコードのサービスから、Amazon SageMaker JumpStartのようなコードベースのソリューションまで、さまざまなツールやサービスについて学びます。
3行まとめ
- 従来MLとジェネレーティブAIの使い分けを明確にし、ハイブリッドアプローチの設計パターンを学べる
- LLMの前段にMLによる分類器を配置することで、より制御されたプロンプトエンジニアリングが可能に
- AWS各サービスのマネージドAPIを組み合わせた実用的なシステム設計の勘所を体験できる
セッション内容
1. 従来の機械学習アプローチの整理

従来のMLは主に以下の3つのパラダイムに分類されます:
- 教師あり学習
- ラベル付きデータを使用
- 分類問題と回帰問題が代表的
- 学習時にground truthが必要
- 教師なし学習
- データの潜在的なパターンを発見
- クラスタリングや次元削減に使用
- 教師データ不要だが、評価が難しい
- 強化学習(DeepRacerで使用)
- 環境との相互作用から学習
- 報酬関数の設計が重要
- 探索と活用のトレードオフが存在
2. MLアルゴリズムの特徴と選択基準
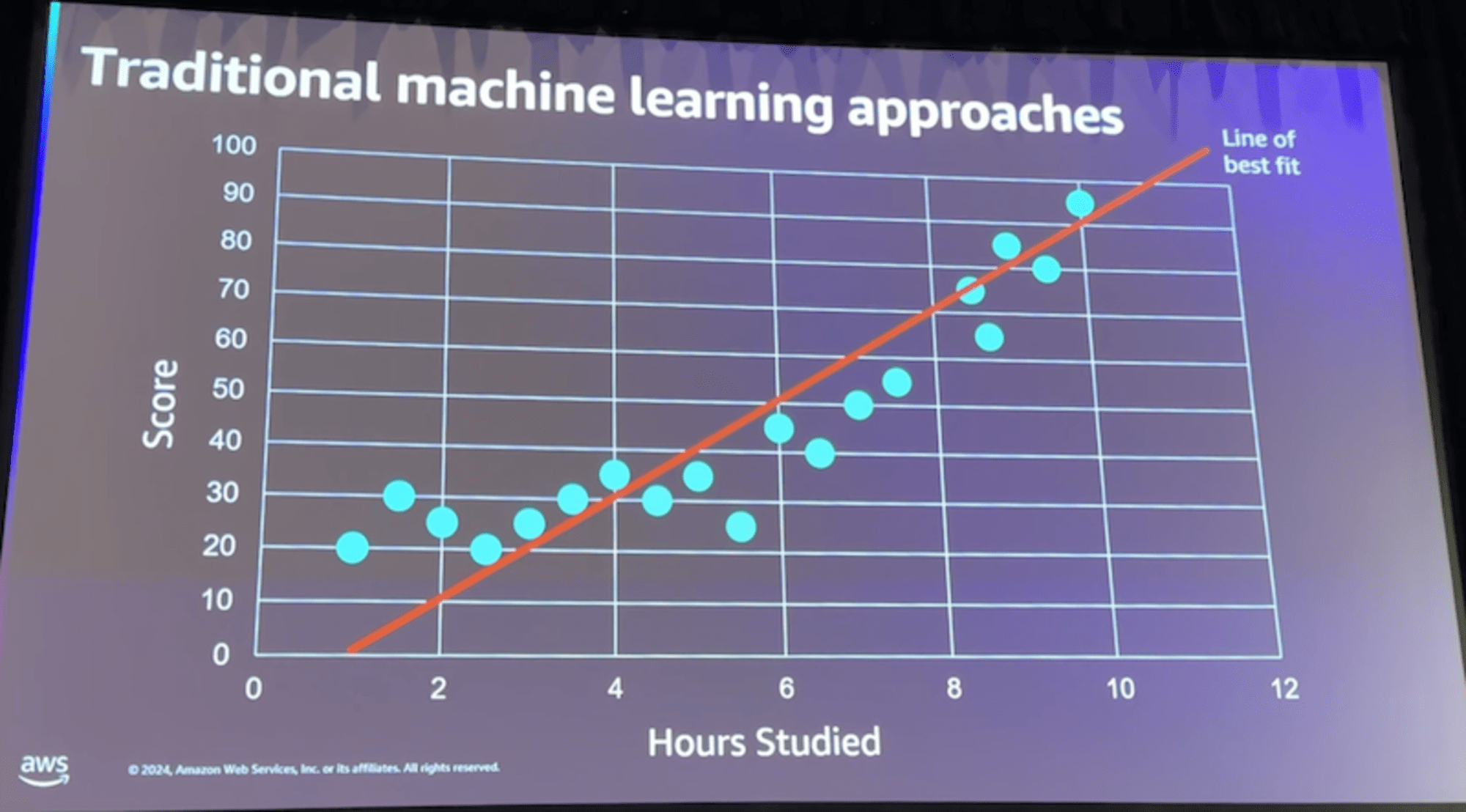
- Linear Learner
# 基本的な使用例
model = LinearLearner(
predictor_type='binary_classifier',
feature_dim=num_features,
mini_batch_size=32
)
- 線形性を仮定した最もシンプルなアルゴリズム
- 特徴量エンジニアリングが重要
- モデルの解釈が容易
- Decision Trees
# 決定木の例
tree_model = DecisionTreeClassifier(
max_depth=5,
min_samples_split=5
)
- 非線形な関係性も捉えられる
- 特徴量の重要度が明示的
- オーバーフィッティングしやすい
- Random Forest
# ランダムフォレストの例
rf_model = RandomForestClassifier(
n_estimators=100,
max_features='sqrt'
)
- 複数の決定木による投票方式
- バギング※1により過学習を抑制
- 計算コストは増加するが精度は向上
※1 バギング(Bagging):Bootstrap Aggregatingの略。データをランダムにサンプリングして複数のモデルを作り、それらの予測を組み合わせる手法
3. ジェネレーティブAIとの統合アプローチ
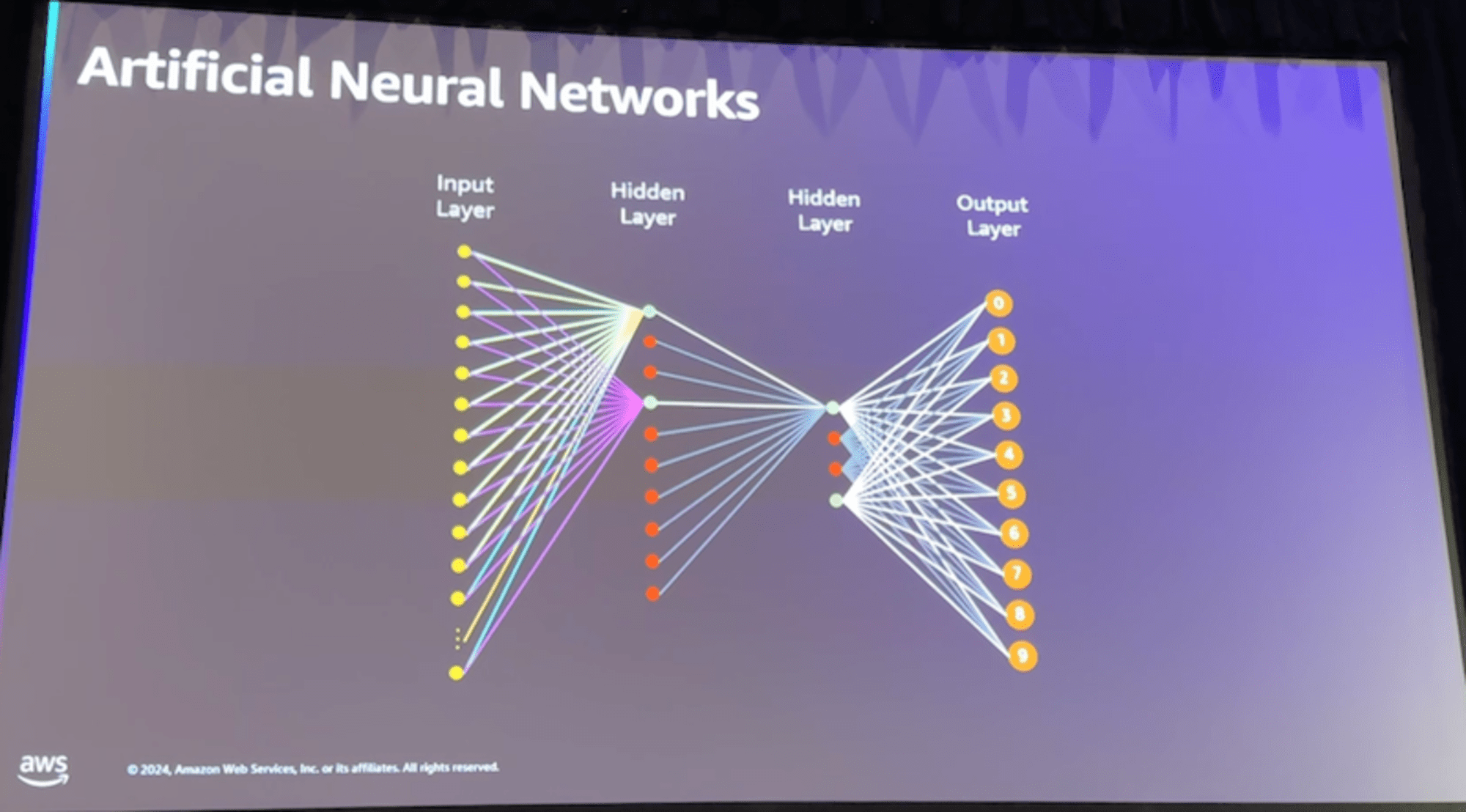
トランスフォーマーアーキテクチャを中心に、以下の点で従来のMLと異なる特徴があります:
- アーキテクチャの違い
- 従来ML:比較的シンプルなネットワーク構造
- 生成AI:Self-Attention※2を活用した複雑な構造
- 学習アプローチ
- 従来ML:タスク特化型の学習
- 生成AI:事前学習+プロンプトエンジニアリング
※2 Self-Attention:入力系列の各要素間の関係性を動的に学習する機構。トランスフォーマーの核となる技術
4. ハンズオン:ハイブリッドシステムの実装
実装したカスタマーサポートシステムの構成:
- 分類器(SageMaker Linear Learner)
# モデルの定義
linear_model = LinearLearner(
role=role,
instance_count=1,
instance_type='ml.m4.xlarge',
predictor_type='multiclass_classifier',
num_classes=len(categories)
)
# 学習データの準備
training_data = sagemaker.inputs.TrainingInput(
s3_data=training_data_path,
content_type='text/csv'
)
- 感情分析(Amazon Comprehend)
# 感情分析の実行
response = comprehend_client.detect_sentiment(
Text=query_text,
LanguageCode='en'
)
sentiment = response['Sentiment']
sentiment_scores = response['SentimentScore']
- 応答生成(Bedrock + Claude)
# Claudeへのプロンプト生成
prompt = f"""
Category: {predicted_category}
Sentiment: {sentiment}
Query: {query_text}
Generate a helpful response considering the above context.
"""
# Bedrockを通じた応答生成
response = bedrock_client.invoke_model(
modelId='anthropic.claude-v3',
contentType='application/json',
body=json.dumps({
'prompt': prompt,
'max_tokens': 500
})
)
実装のポイント:
- MLによる分類でクエリの意図を特定
- 感情分析で緊急度を判断
- LLMの入力プロンプトに文脈情報を付加
まとめ
このワークショップで特に注目すべきは、LLMの前段にMLの分類器を配置するアーキテクチャパターンです。これにより:
- プロンプトエンジニアリングの制御が容易に
- 応答の一貫性が向上
- システムの振る舞いの予測可能性が高まる
また、AWS各サービスのマネージドAPIを組み合わせることで、複雑なMLパイプラインも比較的少ないコードで実装できることが分かりました。
今後は、MLとLLMを組み合わせた同様のアーキテクチャパターンが、チャットボットやドキュメント分析など、様々なユースケースで活用されていくのではないでしょうか。
なお、ワークショップでは日本語での実装例は扱いませんでしたが、日本語対応のために追加で考慮すべき点(トークナイザの選択や前処理の追加など)も今後の検討課題として挙げられそうです。









